
Overview
This 5-day course helps data engineers focus on essential design and architecture while building a data lake and relevant processing platform.
This course is part of the Software Systems series, Data Science series, Graduate Certificate in Big Data Engineering & Web Analytics as well as Graduate Certificate in Engineering Big Data series offered by NUS-ISS.
Course Description & Learning Outcomes
Participants will learn various aspects of data engineering while building resilient distributed datasets. Participants will learn to apply key practices, identify multiple data sources appraised against their business value, design the right storage, and implement proper access model(s). Finally, participants will build a scalable data pipeline solution composed of pluggable component architecture, based on the combination of requirements in a vendor/technology agnostic manner. Participants will familiarize themselves on working with Spark platform along with additional focus on query and streaming libraries. Upon effective completion of the course, participants will be able to: - Understand the growth of big data and need for a scalable processing framework. Understand the fundamental characteristics, storage, analysis techniques and the relevant distributions. - Understand the distributed storage essentials, storage needs, and relevant architectural mechanism in processing large amounts of structured, semi-structured and unstructured data. - Gain expertise with the fault-tolerant computing framework (E.g. YARN) by setting up pseudo cluster nodes or cloud based nodes for processing big data. . - Construct configurable and executable tasks using the In Memory Processing frameworks (E.g. Spark Core). Understand the nuances of writing functional programs and use the core libraries to manipulate the large corpse of unstructured data residing as Resilient Distributed Datasets. - Organize, store and manipulate the collected data using processing libraries. For example, using special statistical operation and stream processing data tools (E.g. Spark Special Libraries). - Understand various data processing, querying and persistence (E.g. Spark QL APIs) available for usage in RDD’s context. - Perform tasks such as filtering, selection and categorization.
Recommended Prerequisites
This is an intensive, intermediate course. This proposed course targets the higher value chain professionals such as data engineers, data application architects, integration architects, software engineers working on data pipeline processing and key technology decision makers. Participants with experience in programming languages such as Python or Java or Scala will benefit more from the course. Participants also need to have a strong interest in building functional pipelines and be comfortable working with Hadoop platform and Spark framework.
Pre-course instructions
- No printed copies of course materials are issued. - Participants must bring their internet-enabled computing device (laptops, tablet etc) with power charger to access and download course materials. Registration close date: 25/09/2023
Schedule
Date: 16 Oct 2023, Monday
Time: 9:00 AM - 5:00 PM (GMT +8:00) Kuala Lumpur, Singapore
Location: NUS-ISS, 25 Heng Mui Keng Terrace, 119615
Date: 17 Oct 2023, Tuesday
Time: 9:00 AM - 5:00 PM (GMT +8:00) Kuala Lumpur, Singapore
Location: NUS-ISS, 25 Heng Mui Keng Terrace, 119615
Date: 18 Oct 2023, Wednesday
Time: 9:00 AM - 5:00 PM (GMT +8:00) Kuala Lumpur, Singapore
Location: NUS-ISS, 25 Heng Mui Keng Terrace, 119615
Date: 19 Oct 2023, Thursday
Time: 9:00 AM - 5:00 PM (GMT +8:00) Kuala Lumpur, Singapore
Location: NUS-ISS, 25 Heng Mui Keng Terrace, 119615
Date: 20 Oct 2023, Friday
Time: 9:00 AM - 5:00 PM (GMT +8:00) Kuala Lumpur, Singapore
Location: NUS-ISS, 25 Heng Mui Keng Terrace, 119615
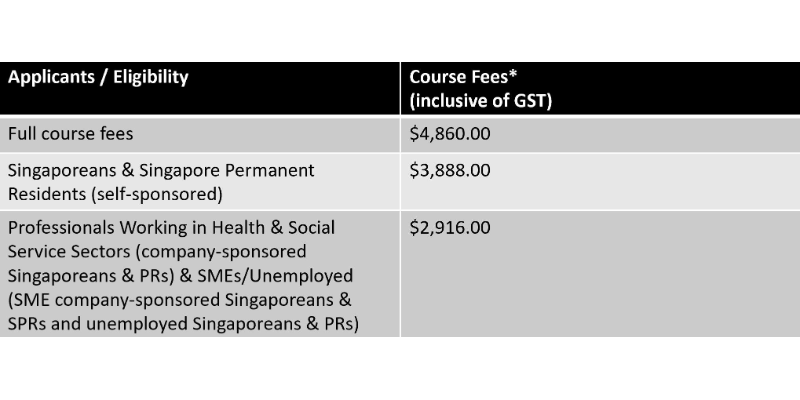
Pricing
Partners



